Abstract
Introduction
Background. Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving collaborative model training. In practice, FL models need to acquire new knowledge continuously while also ensuring the “right to be forgotten” for previously used training data. For example, a year after the launch of ChatGPT, The New York Times accused OpenAI and Microsoft of the unauthorized use of its media data for training, demanding that they delete the acquired knowledge from its models. Furthermore, malicious clients may inject harmful data during training, potentially poisoning the global model. As a result, it is crucial for the global model to eliminate such harmful knowledge. This leads to the concept of Federated Unlearning(FU).
Challenges. In the field of FU, two primary categories of methods have emerged: retraining-based methods and model manipulation-based methods. Among these, retraining-based methods are widely regarded as the state-of-the-art (SoTA) for achieving model unlearning. This approach involves removing the data designated for unlearning and retraining the model from scratch until convergence. Conversely, model manipulation methods modify the model directly using techniques such as gradient ascent, knowledge distillation, and setting parameters to zero to eliminate knowledge. However, existing methods still face several challenges:
- Indiscriminate unlearning: In scenarios where knowledge overlaps occur among clients, traditional methods indiscriminately remove shared knowledge during the unlearning process, leading to a substantial decline in the performance of other clients.
- Irreversible unlearning: In FL systems, clients’ unlearning requests may change dynamically. When a client no longer needs to forget certain knowledge, traditional methods cannot recover that memory quickly.
- Significant unlearning costs: The retraining-based method requires multiple iterations, resulting in significant computational and communication costs. Even simple adjustments to model parameters can demand a significant amount of storage as a compensatory cost.
Method. To address these challenges, we propose a reversible Federated Unlearning method via SElective sparse aDapter (FUSED). To begin, we perform a layer-wise analysis of the model’s sensitivity to knowledge changes, identifying the layers that are most affected. These sensitive layers are then processed into sparse structures known as unlearning adapters. This process, termed Critical Layer Identification (CLI), significantly reduces the number of model parameters, thereby lowering unlearning costs. Subsequently, the unlearning adapters are distributed to clients that do not require unlearning for retraining. During this phase, the original model is frozen, and only the independent unlearning adapters are trained. Ultimately, the unlearning adapters are integrated with the original model to yield a global unlearning model. This method leverages training on the remaining knowledge to effectively overwrite the knowledge that needs to be forgotten, addressing the issue of indiscriminate unlearning. Moreover, the introduction of independent adapters facilitates rapid recovery of forgotten knowledge through their removal and significantly reduces unlearning costs by utilizing sparse parameters. In summary,FUSEDachieves high performance, reversibility, and cost-efficiency in FU, making it suitable for scenarios involving client unlearning, class unlearning, and sample unlearning scenarios.
Contributions. The contributions are as follows:
- We propose FUSED, a reversible FU approach that retrains independent sparse adapters for unlearning. These adapters effectively mitigate unlearning interference while ensuring that the unlearning is reversible.
- We introduce the CLI method which accurately identifies the model layers sensitive to knowledge changes and constructs sparse unlearning adapters, resulting in a significant reduction in parameter scale and lowering unlearning costs.
- We theoretically and experimentally prove the effectiveness of the proposed method across different unlearning scenarios in FL, including client unlearning, class unlearning, and sample unlearning.
Methodology
FUSED involves a two-stage unlearning process (as shown in method figure). The first stage is Critical Layer Identification (CLI), and the second stage is Unlearning via Sparse Adapters, which is based on the critical layers identified.
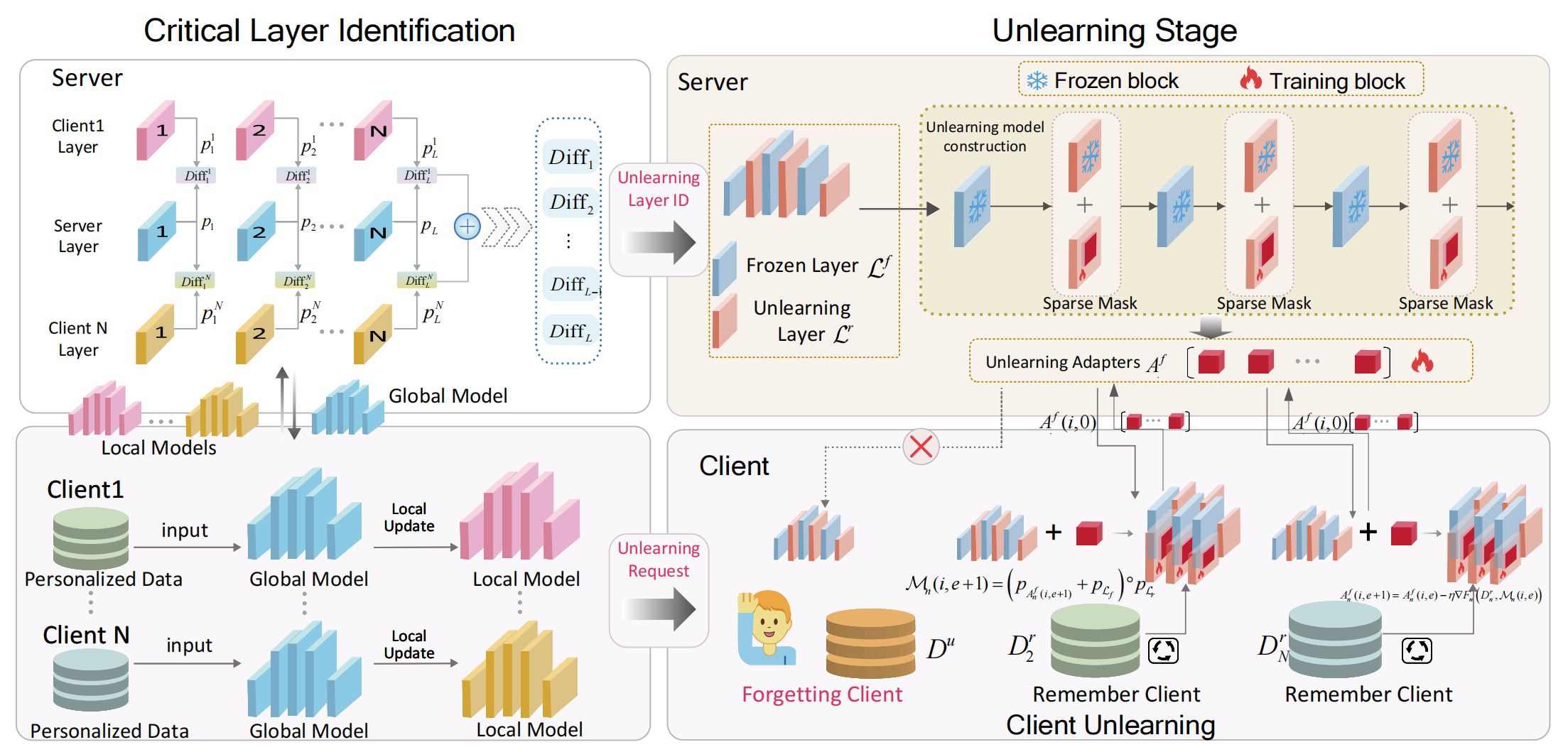
Critical layer identification
During the CLI phase, each client, coordinated by the server, participates in a federated iteration process. Clients receive the global model distributed by the server and train it using their local data before uploading it back to the server. Subsequently, the distance between the parameters of each layer in the models from different clients and those in the corresponding layers of the initial model is calculated by the server. The layers with the most significant parameter changes are obtained by averaging these distances.
Consider a global model with $L$ layers, and $N$ clients, each with an identical model structure. After local training, the parameters of these models differ across clients. Let $p_l^n$ represent the parameters of the $l$-th layer of the $n$-th client, where $n = 1,2, \cdots ,N$ and $l = 1,2, \cdots ,L$. The initial distributed global model is denoted as $\mathcal{M}^r = { { {p_1},{p_2}, \cdots ,{p_L} } }$. After local training by the clients, the variation in the $l$-th layer of the model can be expressed as: \(Diff_l = Diff_l^1(p_l^1,{p_l}) \oplus \cdots \oplus Diff_l^N(p_l^N,{p_l}),\) where $Diff_l^n(p_l^n,{p_l})$ represents the difference between the $l$-th layer of the $n$-th client’s model and the $l$-th layer of the original model (need to be forgotten) distributed by the server. We utilize the Manhattan distance for measurement. Assuming that the dimensions of $p_l^n$ and $p_l$ are $k \times v$. The calculation process is as follows:
\[{\cal D}iff(p_l^n,{p_l}) = \sum\nolimits_{i = 1}^k {\sum\nolimits_{j = 1}^v {\left| {p_{l,ij}^n - {p_{l,ij}}} \right|} }.\]The aggregation method of $\oplus$ is as follows:
\[\begin{array}{l} Diff_l^1(p_l^1,{p_l}) \oplus {\cal D}iff_l^N(p_l^N,{p_l})= \frac{{\left| {{D_1}} \right|}}{{\sum\nolimits_{n = 1}^N {\left| {{D_n}} \right|} }}\\ Diff_l^1(p_l^1,{p_l}) + \frac{{\left| {{D_1}} \right|}}{{\sum\nolimits_{n = 1}^N {\left| {{D_n}} \right|} }}{\cal D}iff_l^N(p_l^N,{p_l}), \end{array}\]where $\left|D_i\right|$ represents the data volume of client $i$. Eventually, $LS = \left[ {\mathop {\arg \max }\limits_l { Diff_l} , \cdots ,\mathop {\arg \min }\limits_l { Diff_l} } \right]$ indicating the changes in different model layers is obtained. The first element corresponds to the layer index that is most sensitive to changes in client knowledge, while the last element corresponds to the most robust layer. To minimize resource cost, the subsequent unlearning process prioritizes unlearning in the most sensitive model layers.
Unlearning via sparse adapters
Based on the list obtained from CLI, given a preset value $K$ for the number of layers to be unlearned, the first $K$ indices in $LS$ are designated for FU. Let $\mathcal{L}^f$ denote the set of layers that need to be unlearned, and $\mathcal{L}^r$ denote the remaining frozen layers. For each unlearning layer in $\mathcal{L}^f$, we discard most of the parameters in a random manner and leave only a small portion, forming a sparse parameter matrix ${A^f}$. During training, only ${A^f}$ is trained while $\mathcal{L}^f$ remains unchanged. In the inference process, the new parameters of the unlearning layer are directly obtained by adding the parameters of ${A^f}$ (denoted by ${p_{A^f}}$) and $\mathcal{L}^f$ (denoted by ${p_{{{\mathcal{L}}^f}}}$).
For the original model $\mathcal{M}^r$, the entire unlearning process
can be divided into four stages: model distribution, local training,
model uploading, and model aggregation. In FUSED, there are
significant differences in the model distribution and local training
stages compared to traditional FL. The following sections will primarily
focus on these two stages. Firstly, during the model distribution stage,
the model is only distributed to clients that contain the remembered
dataset $\mathcal{D}^r$ (see Problem Formulation), and only unlearning
adapters are transmitted. This means that in client unlearning
scenarios, the clients to be forgotten will not receive the
adapters[^1]. Additionally, the distributed model is a sparse matrix
${A^f}$, which significantly reduces communication overhead. Secondly,
in the local training stage, for a client $n$, assuming the total number
of local training epochs per federated iteration is $E$, then in the
$t$-th federated iteration, the parameters of the model
$\mathcal{M}_n(i,e)$ are
$({p_{A_n^f(i,e)}} + {p_{{{\mathcal{L}}^f}}}) \circ {p_{{{\mathcal{L}}^r}}}$. The training process is as follows:
\(A_n^f(i,e + 1) = A_n^f(i,e) - \eta \nabla {F_n}(D_n^r,{{\cal M}_n}(i,e)),\) \({{\mathcal{M}}_n}(i,e + 1) = ({p_{A_n^f(i,e + 1)}} + {p_{{{\cal L}_f}}}) \circ {p_{{{\cal L}_r}}}.\)
Experiment
Experimental setting
The experiments are built on PyTorch 2.2.0, developing an FL framework comprising one server and 50 clients. The hardware environment uses an NVIDIA RTX 4090. Optimizers consisting of SGD and Adam are employed with a batch size of 128. The result is listed in the following table.
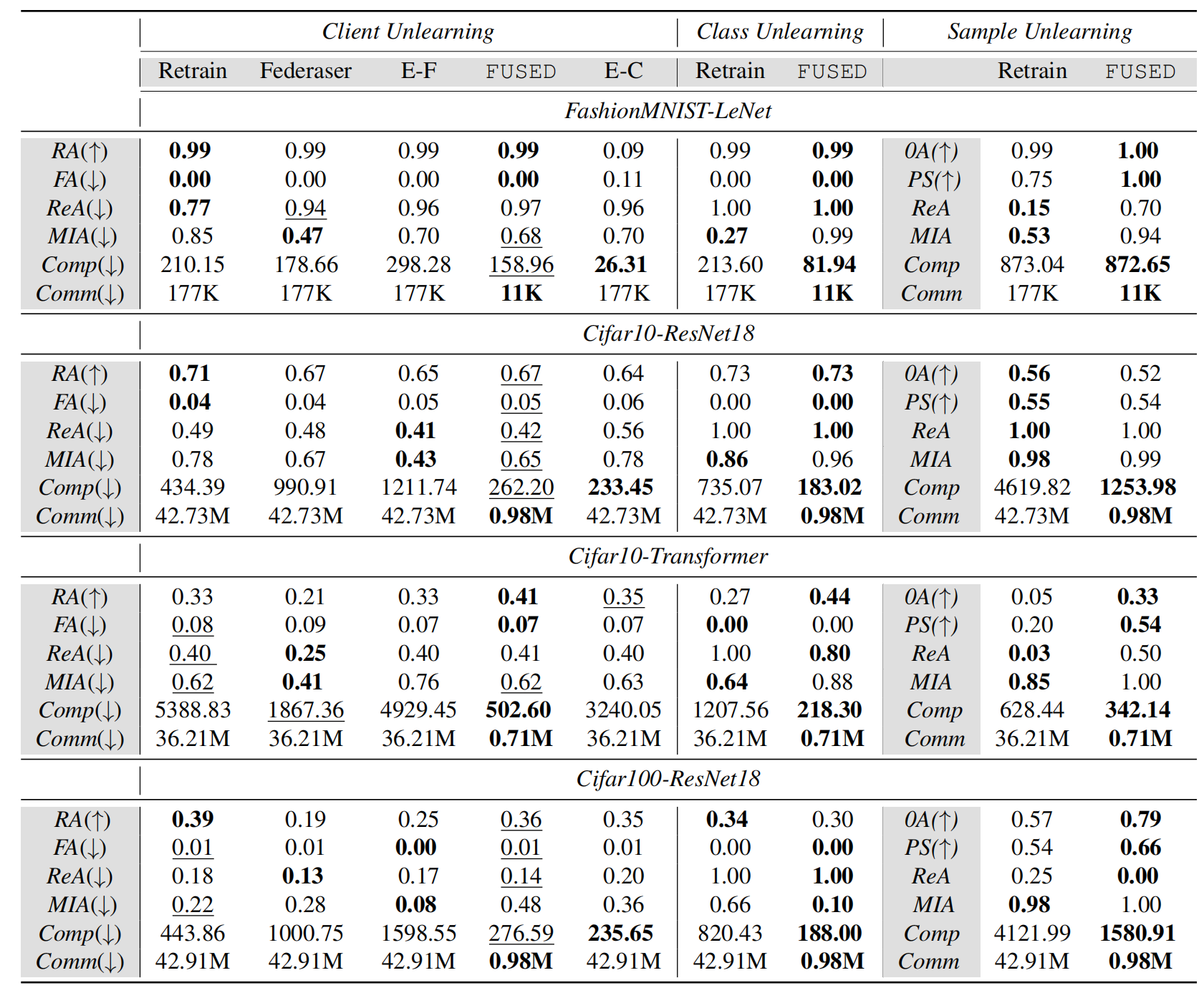
The datasets include FashionMNIST, Cifar10 and Cifar100. We use the Dirichlet function to partition the dataset and conduct tests under two conditions: $\alpha = 1.0$ and $\alpha = 0.1$. In the main result table, we primarily present the results for $\alpha = 1.0$; for the results under non-independent and identically distributed, please refer to the appendix. The model used for FashionMNIST is LeNet, while ResNet18 is employed for training on Cifar100. For Cifar10, training is conducted using both ResNet18 and a vision-based Transformer model called SimpleViT. Baselines include Retraining, Federaser, Exact-Fun, and EraseClient. Among these, Retraining is the upper bound of unlearning; it can achieve the effect of the model having never encountered the forgotten data.
Evaluations. We evaluate FUSED from multiple perspectives:
-
RA & FA: RA is the testing accuracy on the remaining dataset, which should be as high as possible to minimize knowledge interference. FA is the testing accuracy on the unlearned dataset, which should be as low as possible.
-
Comp & Comm: Comp is the time to complete pre-defined unlearning iterations; Comm denotes the data volume transmitted between a single client and the server.
-
MIA: the privacy leakage rate after unlearning, which is assessed in the context of membership inference attacks. Assuming that the forgotten data is private, a lower inference accuracy of the attack model indicates less privacy leakage.
-
ReA: the accuracy of relearning, which refers to the accuracy that can be achieved after a specified number of iterations to relearn the unlearned knowledge. If the unlearned knowledge is effectively erased, the accuracy achieved during the subsequent relearning will be lower.
Critical layer identification
Before conducting unlearning, it is essential to identify the layers that are sensitive to knowledge. We segment the client data using a Dirichlet distribution with a parameter $\alpha$ of 0.1 to enhance knowledge disparity among clients. For the Cifar10 and Cifar100 datasets, we employ the ResNet18 and SimpleViT models, while the LeNet model is utilized for FashionMNIST. After obtaining locally trained models from different clients, we can observe the average change in each layer. In Fig.2, we present the Diff values for each layer of the ResNet18 and SimpleViT across different training iterations. We can see the last, second-to-last, sixth-to-last, and eighth-to-last layers of the ResNet18 model, and the last several layers of the Transformer model demonstrate heightened sensitivity to data variations across clients. Therefore, these layers will be designated as unlearning layers for sparse training in the subsequent unlearning process.
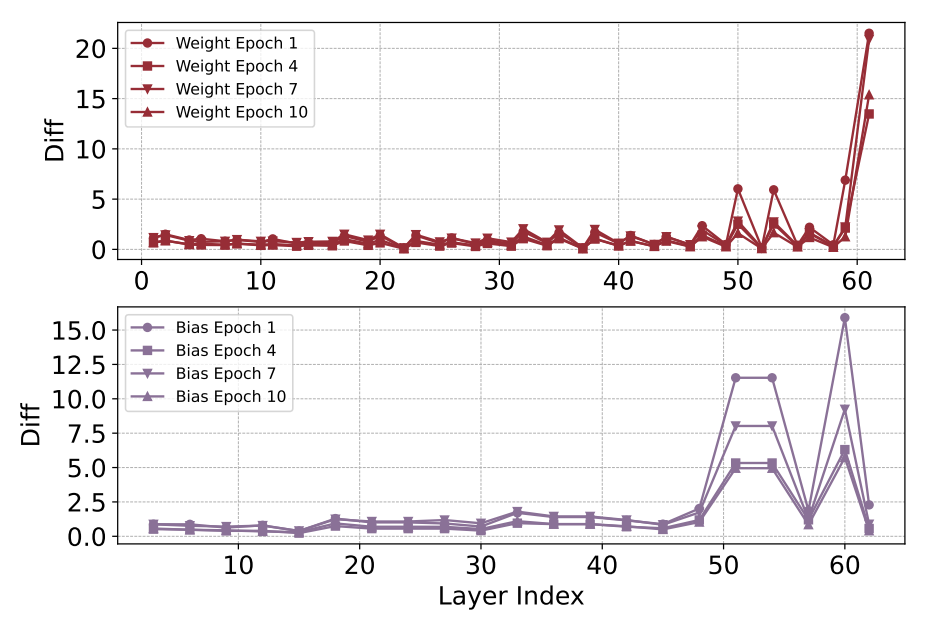

In fact, with the increasing number of federated iterations, the global model’s knowledge generalization ability improves, leading to a gradual reduction in the gap of Diff values between layers. As illustrated in Fig.2 and Fig.3, the gap is most pronounced when Epoch=1. However, as the number of iterations increases, this disparity decreases. Therefore, by comparing the model after a single federated iteration, it is possible to more precisely identify the critical layers sensitive to knowledge.
Results Analysis
Unlearning performance. In the client unlearning scenario, we use
clients affected by Byzantine attacks as test cases. The mode of attack
is label flipping, where one client’s label is maliciously manipulated,
resulting in a demand for unlearning. From the main result table,
it can be observed that among the three metrics that directly measure
forgetting effects—RA, FA, and ReA—only FUSED is nearly on
par with Rrtraining. This approach maintains a low accuracy on unlearned
data while achieving a high accuracy on others, and even demonstrates
overall superiority compared to Rrtraining, particularly in the
Transformer model. It can be concluded that FUSED effectively unlearns
the specified client knowledge while minimizing the impact on the
original knowledge. This is attributable to the method proposed in this
paper, which freezes the parameters of the original model and only
trains the unlearning adapter, thereby avoiding direct modifications to
the old knowledge and effectively reducing interference with the
existing knowledge. Similarly, the same results are observed in class
and sample unlearning; for further analysis, please refer to the
Appendix.
Knowledge interference. To investigate the impact of unlearning on
the overlapping knowledge across clients, we use the Cifar10 dataset,
distributing 90% of the data labeled as 0 and all data labeled as 1 to a
client that needs to be forgotten. The remaining data, labeled from 2 to
9, and 10% of the data labeled as 0, are randomly assigned to other
clients. After unlearning, we evaluate the accuracy of the knowledge
unique to the unlearning client (data labeled as 1), the accuracy of the
overlapping knowledge (data labeled as 0 from the remaining clients),
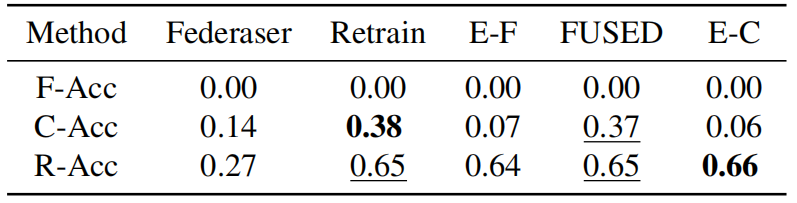
and the accuracy of the knowledge unique to the remaining clients (data
labeled from 2 to 9). The final results are shown in Tab.2. It can be observed that all methods completely forget the knowledge unique to the forgetting client, while only the
FUSED method demonstrates improved performance on overlapping
knowledge compared to Retraining. Therefore, FUSED can reduce
knowledge interference.
Unlearning cost. In the unlearning process, resource overhead is an
inevitable problem. Tab.1 primarily illustrates the consumption of
computational and communication resources. Since the FUSED trains and
transmits only the sparse adapters, it consistently demonstrates a
significant advantage across nearly all unlearning scenarios and
datasets. Additionally, in terms of storage resources, both Federaser
and EraseClient require the retention of all client models and the
global model during each round, which presents significant challenges
regarding storage capacity. This demand increases exponentially with the
number of clients and iterations, rendering it impractical in real-world
applications. In contrast, FUSED only requires the storage of a
complete global model and its adapters. Moreover, when compared to the
retraining method, the retraining method achieves RA/FA values of
0.71/0.04 when data is complete, and FUSED achieves RA/FA values of
0.67/0.05. When we reduce the number of retraining data by half, FUSED
maintains RA/FA values of 0.65/0.03, indicating no significant decline
in unlearning performance. This suggests that FUSED can achieve
results comparable to retraining with less data, thereby conserving
storage resources.
Privacy protection. When unlearned data is users’ privacy, even if
the model shows great unlearning performance, an attacker may still be
able to discern which data corresponds to unlearned private information
and which does not, particularly in the context of member inference
attacks. Therefore, it is crucial to evaluate the privacy leakage rate
of the model after unlearning. The MIA values for FUSED are
generally comparable to those of the Retraining method, and in most
instances, they remain at a relatively low level. This indicates that
FUSED’s capability to mitigate privacy leakage is on par with that of
other methods.
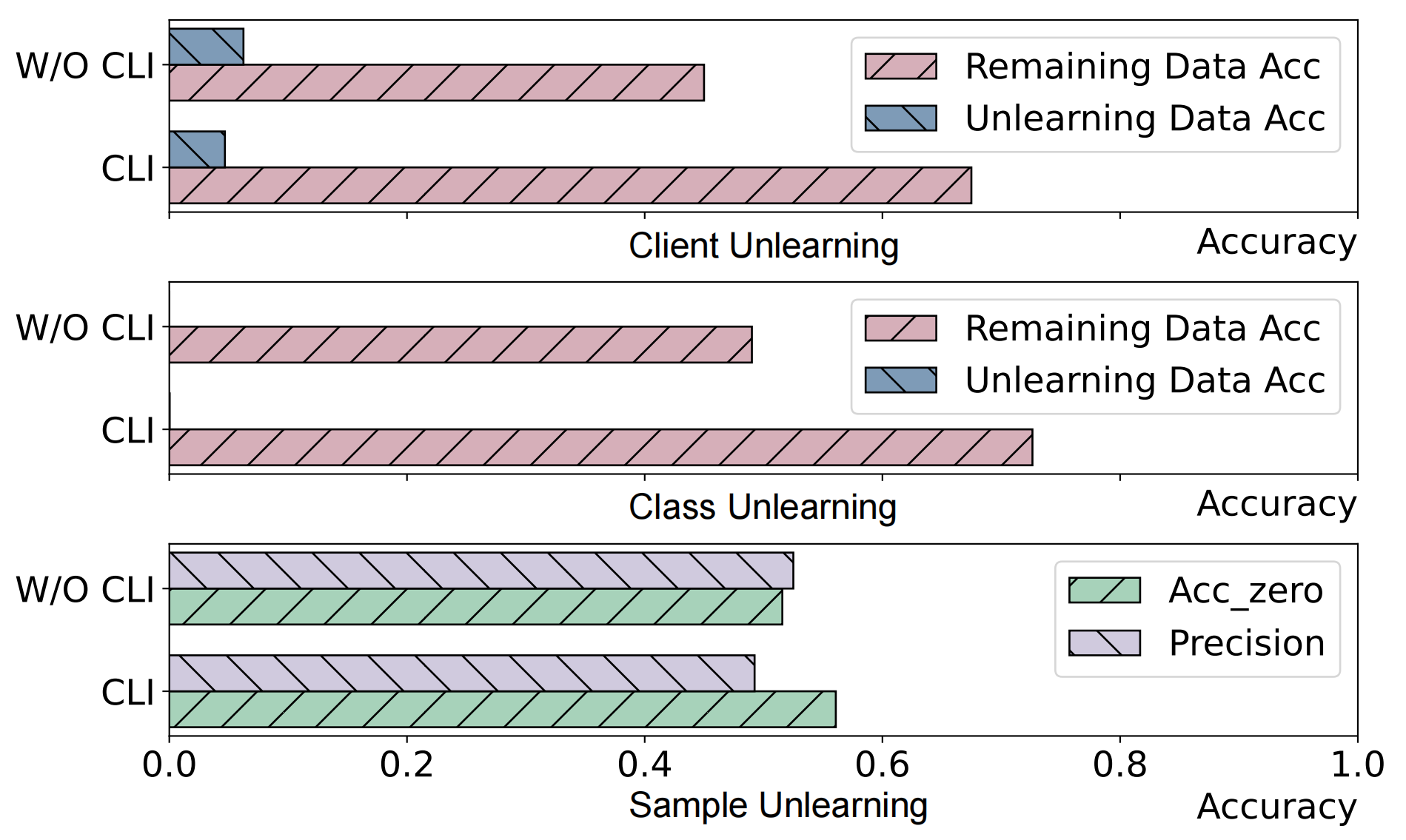
Ablation study. To illustrate the necessity of CLI, we conduct an
ablation study using the Cifar10 dataset, with the experimental results
presented in Fig.4. In Fig.4, “W/O CLI" denotes the effect of FUSED
achieved by randomly selected layers. It is evident that, with the
implementation of CLI, the accuracy of remaining knowledge is higher in
both client unlearning and class unlearning scenarios. Although the
disparity is smaller in sample unlearning, it still maintains a
comparable level. This indicates that CLI can more accurately identify
the model layers that are more sensitive to knowledge, thereby enhancing
the unlearning effect.
Conclusion and discussion
Conclusion. This paper focuses on the problem of unlearning within FL. To address the challenges of indiscriminate unlearning, irreversible unlearning, and significant unlearning costs, we propose a reversible federated unlearning method via selective sparse adapters (FUSED). Firstly, by comparing the client model with the server model, we identify critical layers to unlearn. Then, independent sparse unlearning adapters are constructed for each unlearning layer. After that, only the sparse adapters are retrained, achieving efficient resource utilization. In this way, FUSED greatly reduces the knowledge interference. Furthermore, independent adapters are easy to remove to facilitate memory recovery. Finally, we validate FUSED in client unlearning scenarios based on Byzantine attacks, sample unlearning scenarios based on backdoor attacks, and class unlearning scenarios. The results show that FUSED’s unlearning effectiveness matches that of Retraining, surpassing other baselines while significantly reducing costs.
Discussion. In addition to unlearning, the proposed adapters can also serve as knowledge editors, adjusting the model’s knowledge on different occasions. For instance, they can help unlearn private information and overcome catastrophic forgetting simultaneously. Moreover, when the knowledge editing requirements vary among clients, combinations of adapters can enhance global generalization. However, there are some limitations of FUSED we can not overlook, for example, it still requires a great number of remaining data to train the adapters. Some techniques like data compression are expected to solve this problem. Meanwhile, compared to some methods that only adjust parameters on the server, the FUSED method, which is based on retraining, requires the participation of all clients that contain residual knowledge, demanding a higher level of client engagement.
Citation
@inproceedings{
zhong2025unlearning,
title={Unlearning through Knowledge Overwriting: Reversible Federated Unlearning via Selective Sparse Adapter},
author={Zhengyi Zhong, Weidong Bao, Ji Wang, Shuai Zhang, Jingxuan Zhou, Lingjuan Lyu and Wei Yang Bryan Lim},
booktitle={Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025},
url={https://openreview.net/forum?id=3EUHkKkzzj}
}